This project demonstrates how to build an intelligent search layer using tool calling and building analytics layer on top of Uber receipts using AWS Bedrock Agents and Elasticsearch.
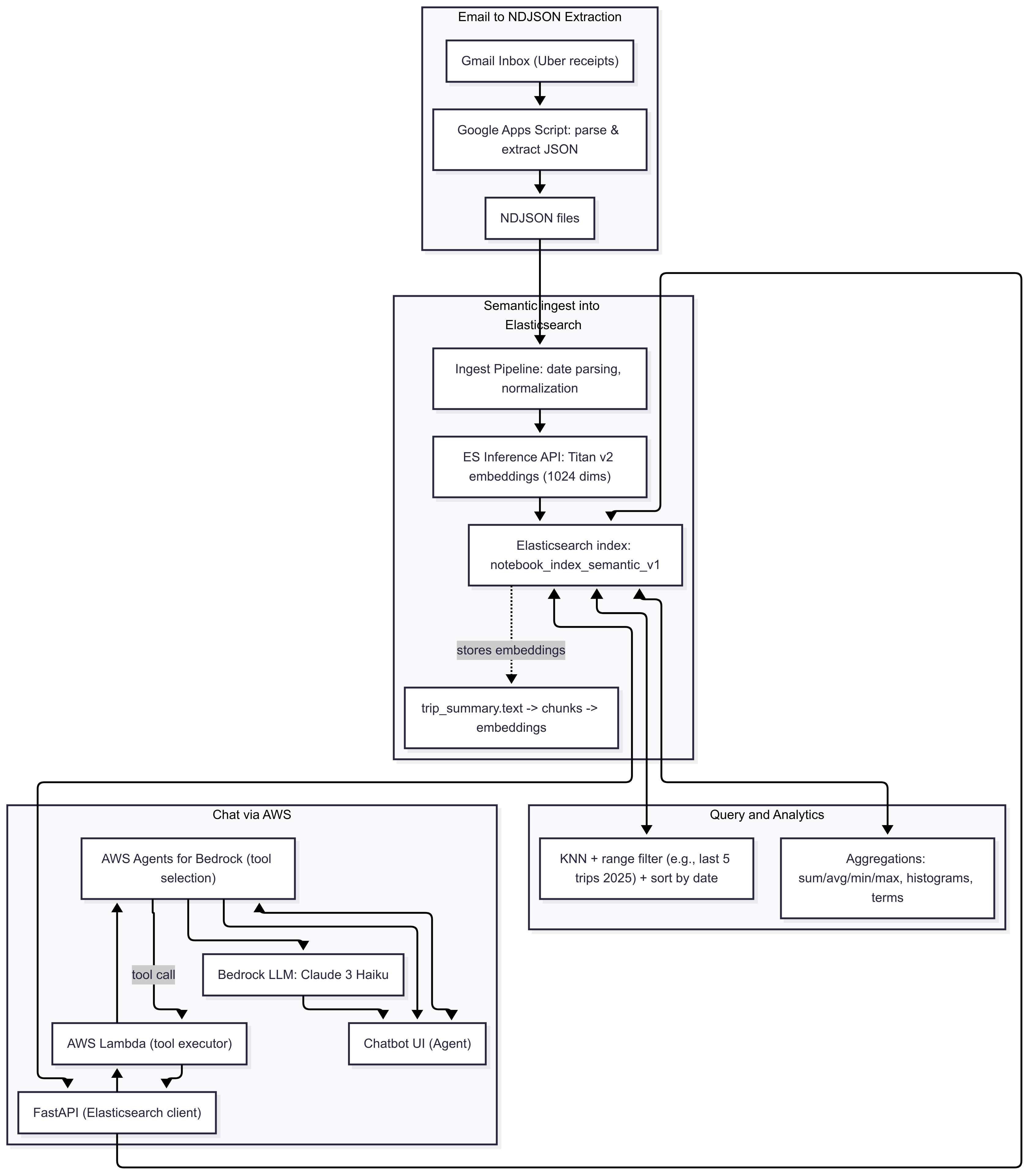
Uber Receipts from Gmail are parsed with Google Apps Script to extract structured trip details (pickup, drop-off, fare, duration, promotions, driver, etc.). These records are stored as NDJSON and ingested into an Elasticsearch index with semantic embeddings generated through the Amazon Titan v2 embedding model.
On top of this data, we enable:
- Semantic search using KNN queries on embeddings.
- Aggregations and analytics for metrics such as longest trip, highest fare, shortest distance, and frequent pickup/drop-off locations.
- Time-based insights including daily, monthly, and 30-minute travel windows with fare statistics.
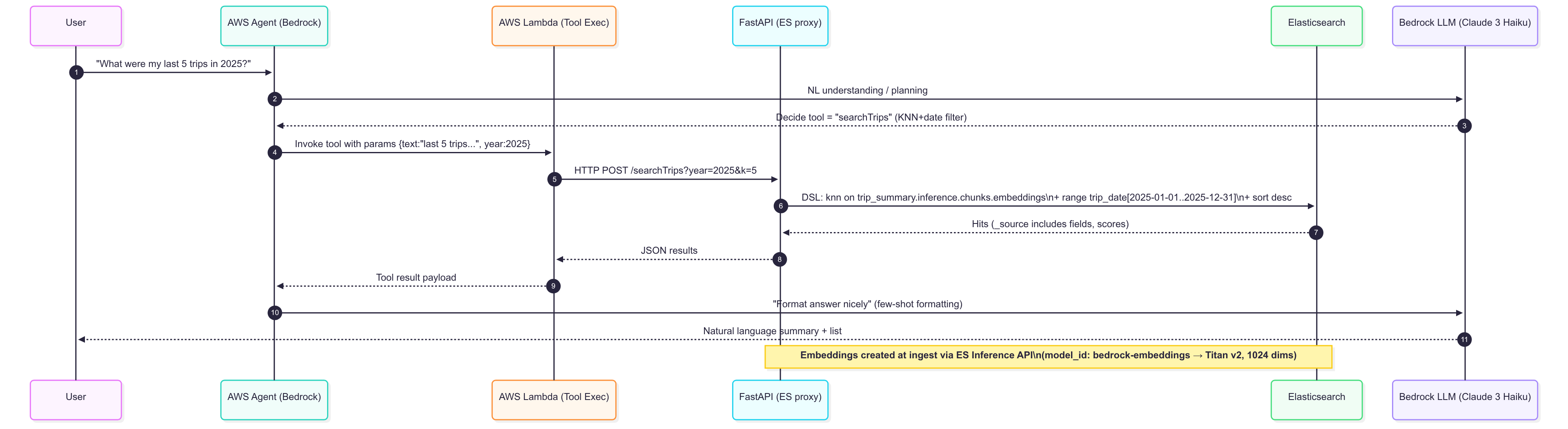
An AWS Bedrock Agent acts as the conversational layer, for basic checks, you can even try with Elasticsearch Playground. It decides which Elasticsearch query or aggregation to run by function calling via the Lambda & bedrock model to FastAPI service. Responses are then summarized naturally using Claude 3 Haiku, making it possible to ask open-ended questions like:
- Show me my last 5 trips in 2025.
- What was the most expensive trip I took last year?
- Which pickup location did I use most often?
High Level Architecture
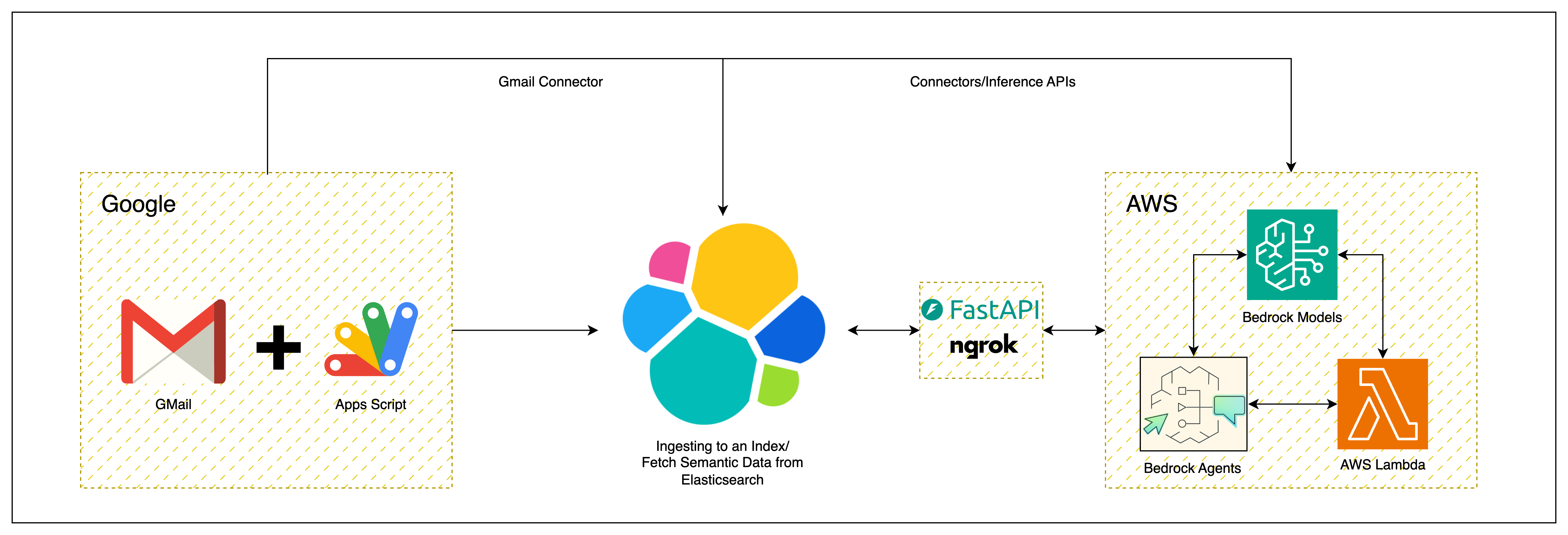
Sequence Diagram
Here’s the quick overview from user perspective:
Data Flow Chart
For AWS related dependencies, refer below:
For Google Apps Script dependencies:
Usage of Google Apps Script, makes it easy for everyone to extract data from GMail with just a simple UI/login authorization.
Let’s start from Elasticsearch:
-
Start with Elastic Cloud, easy to start or you can make use of start-local. For the demo purpose, I’m using Elasticsearch version
8.17.5. -
Once, Elasticsearch is up and running. We can make use of
semantic_textfield that generates the embeddings on the fly. To do that,text_embeddingsinference API.
To do that, you would need to create those text_embeddings tasks:
# embedding task
PUT _inference/text_embedding/bedrock-embeddings
{
"service": "amazonbedrock",
"service_settings": {
"access_key": "XXXXXXXXXXXXXXXXXXXXX",
"secret_key": "XXXXXXXXXXXXXXXXXXXXXgLdX+jjuHk1o1bLMY",
"region": "<appropriate_region>",
"provider": "amazontitan",
"model": "amazon.titan-embed-text-v2:0"
}
}
# completion task
PUT _inference/completion/bedrock-completion
{
"service": "amazonbedrock",
"service_settings": {
"access_key": "XXXXXXXXXXXXXXXXXXXXX",
"secret_key": "QXXXXXXXXXXXXXXXXXXXXXdX+jjuHk1o1bLMY",
"region": "<appropriate_region>",
"model": "anthropic.claude-3-haiku-20240307-v1:0",
"provider": "anthropic"
}
}
Once, your inference endpoints are created. We are now good to import.
- You can ingest/load the NDJSON data to Elasticsearch (example.uber_trips.ndjson) from the GMail. Make sure, you sanitize your data(test it before you upload or ingest to Elasticsearch). While uploading the data, make sure to update the
@timestamp==pickup_timestampfield so that it can plot thedateswithtime windowaccordingly.
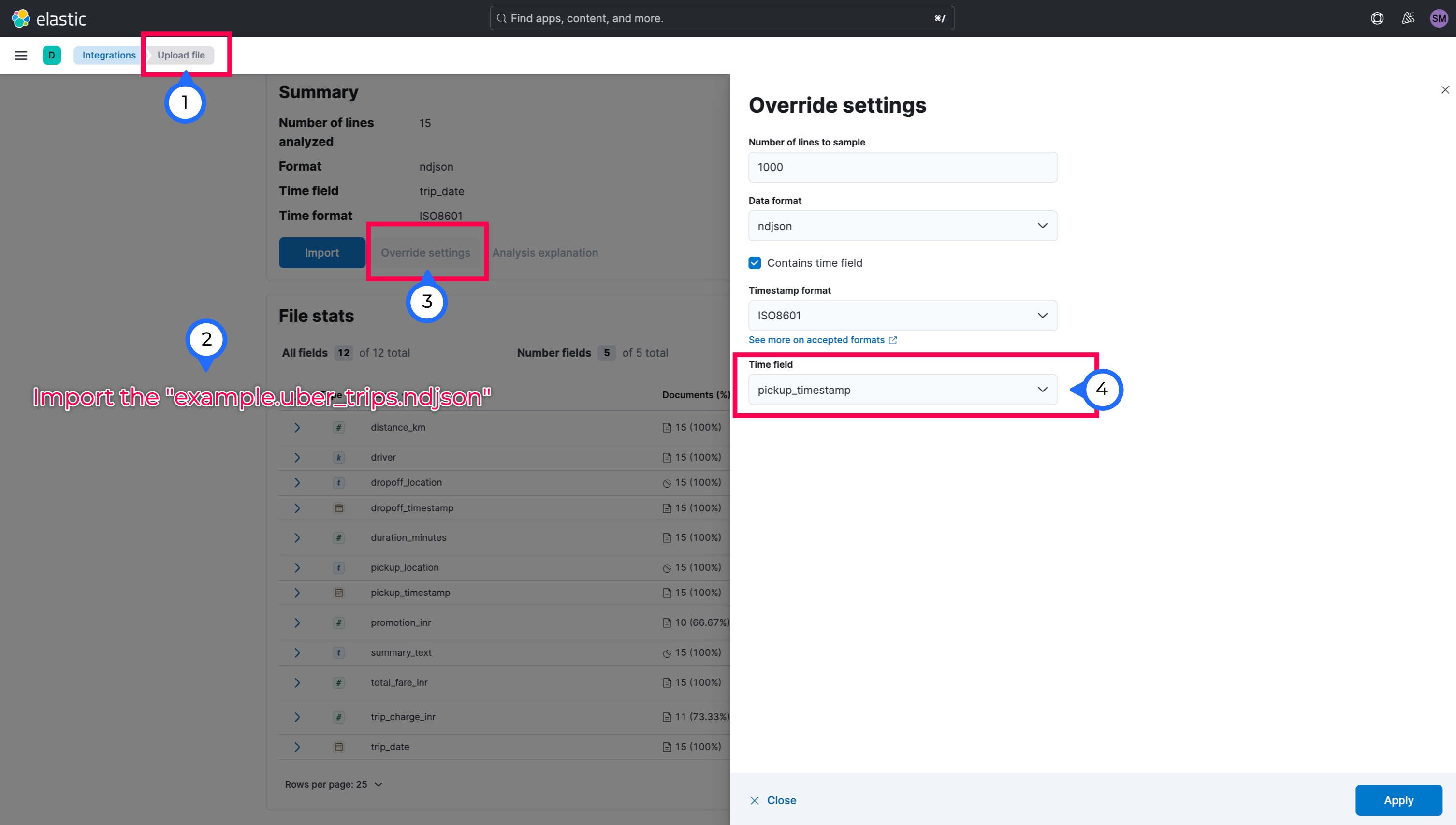
While importing, make sure to change the index(notebook_index_semantic_v1) creation to Advanced and update the below:
# mappings
{
"properties": {
"@timestamp": {
"type": "date"
},
"distance_km": {
"type": "double"
},
"driver": {
"type": "keyword"
},
"dropoff_location": {
"type": "text"
},
"dropoff_timestamp": {
"type": "date",
"format": "iso8601"
},
"duration_minutes": {
"type": "long"
},
"pickup_location": {
"type": "text"
},
"pickup_timestamp": {
"type": "date",
"format": "iso8601"
},
"promotion_inr": {
"type": "double"
},
"summary_text": {
"type": "text"
},
"total_fare_inr": {
"type": "double"
},
"trip_charge_inr": {
"type": "double"
},
"trip_date": {
"type": "date",
"format": "iso8601"
},
"trip_summary": {
"type": "semantic_text",
"inference_id": "bedrock-embeddings"
}
}
}
# ingest pipeline
{
"description": "Ingest pipeline created by text structure finder",
"processors": [
{
"date": {
"field": "pickup_timestamp",
"formats": [
"ISO8601"
]
}
},
{
"set": {
"field": "trip_summary",
"copy_from": "summary_text"
}
}
]
}
(Please note, it will take time to import and prior to import, make sure in the Elasticsearch Relevance page, you got the inference deployed)
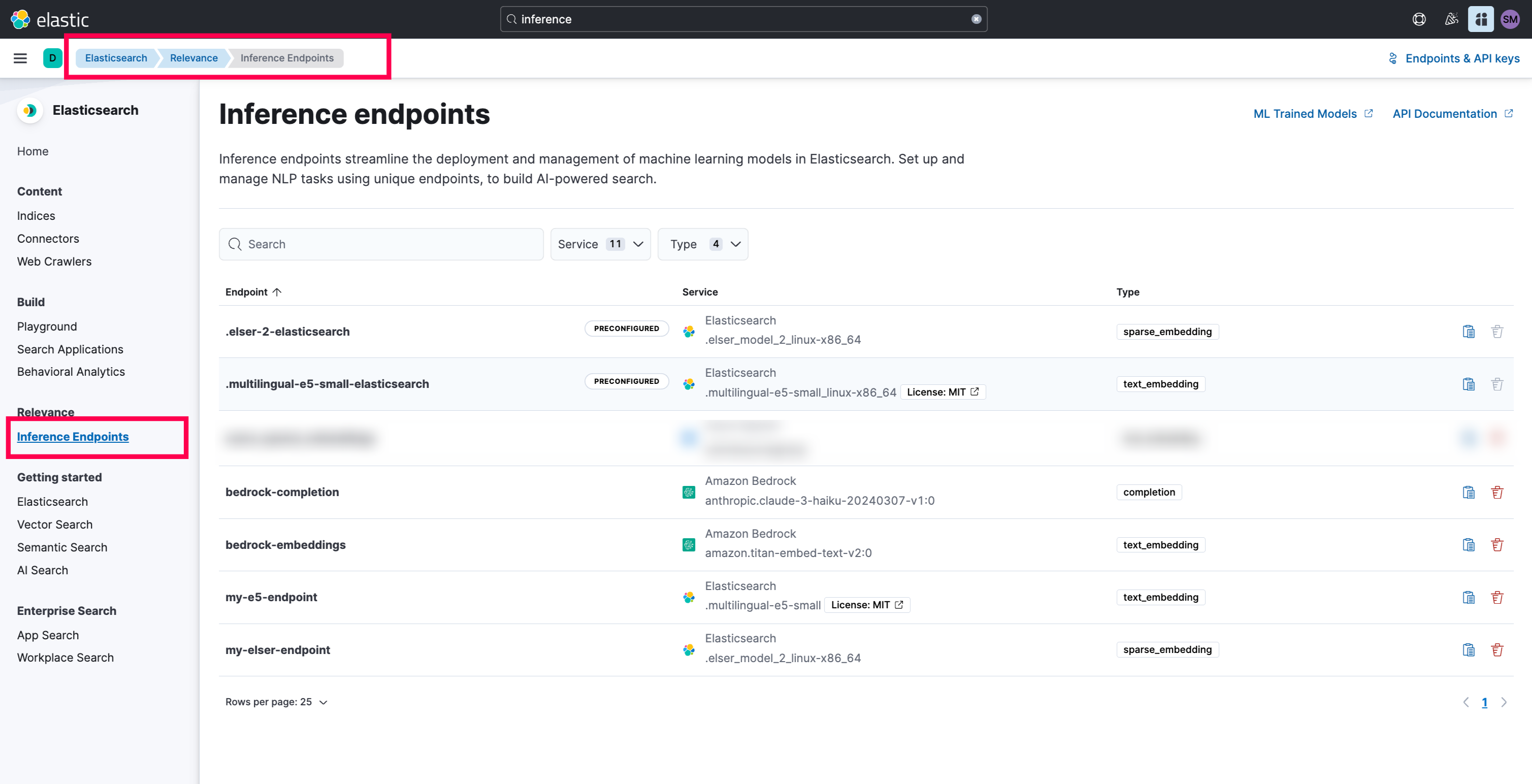
- You can also try the below query to test it:
# To get the mappings:
GET notebook_index_semantic_v1/_mapping
# To test the retrieval of the appropriate chunks and documents
GET notebook_index_semantic_v1/_search
{
"knn": {
"field": "trip_summary.inference.chunks.embeddings",
"query_vector_builder": {
"text_embedding": {
"model_id": "bedrock-embeddings",
"model_text": "last 5 trips in the year 2025"
}
},
"k": 2,
"num_candidates": 10
},
"query": {
"bool": {
"filter": {
"range": {
"trip_date": {
"gte": "2025-01-01",
"lte": "2025-12-31"
}
}
}
}
},
"_source": {
"includes": ["trip_summary.text","distance_km","driver","duration_minutes","promotion_inr","total_fare_inr","trip_charge_inr","trip_date"]
}
}
- Once the query is answered, let’s get the Personal API Key and Elasticsearch Endpoint and paste it in the .env file
Quick Testing:
- You can test the capabilities of the
semantic searchusingElasticsearch Playground.
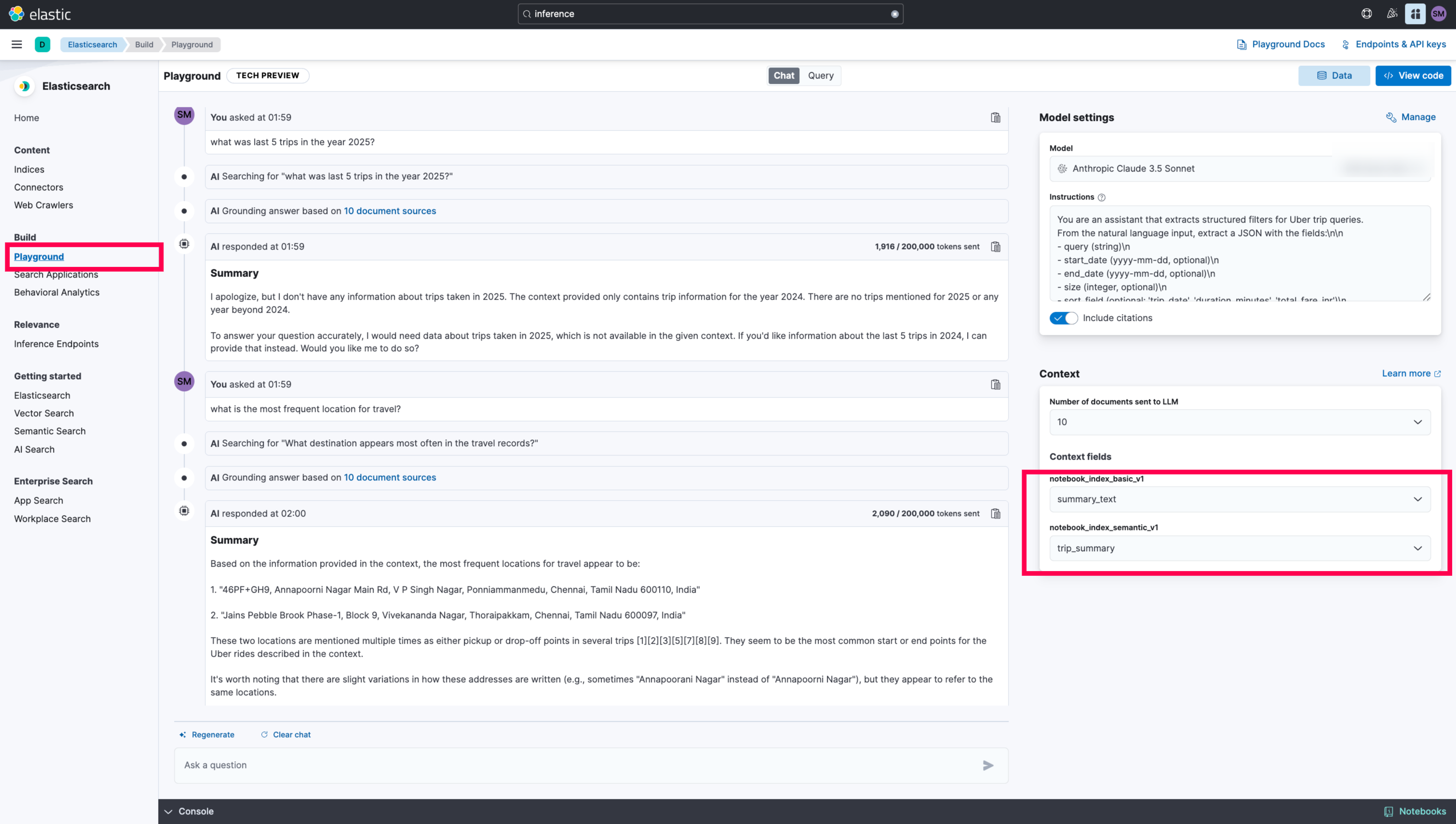
-
The limitation of the playground is that the inability to optimize the queries or tune it accordingly. It’s well suited for
Text interpretationthanAnalyticstype data. -
Now, this confirms that the setup on the
Elasticsearchside is completed.
NGROK Setup
- Login to NGROK and fetch the auth token and install ngrok aprpropriately. Make sure to paste it in the .env file
Start the FastAPI Application(triggers NGROK):
#1 python -m venv venv
#2 source venv/bin/activate
#3 pip install -r requirements.txt
#4 cd src
#5 python main.py
# Expected Output
(venv) bedrock-agents-elasticsearch-demo % python main.py
🚀 Public URL: https://1f92b42936a3.ngrok-free.app
INFO: Started server process [59221]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
INFO: 44.246.220.86:0 - "GET /topTrips/stats/totalDistance?date_lte=2025-12-31&date_gte=2025-01-01 HTTP/1.1" 200 OK
INFO: 44.246.220.86:0 - "GET /topTrips/stats/totalDistance?date_lte=2024-12-31&date_gte=2024-01-01 HTTP/1.1" 200 OK
INFO: 44.246.220.86:0 - "GET /searchTrips?sort_order=asc&date_lte=2025-01-31&size=5&model_text=first+5+trips+in+January+2025&date_gte=2025-01-01 HTTP/1.1" 200 OK
INFO: 44.246.220.86:0 - "GET /topTrips/byField?sort_order=desc&field=total_fare_inr&date_lte=2025-12-31&size=1&date_gte=2025-01-01 HTTP/1.1" 200 OK
INFO: 44.246.220.86:0 - "GET /topTrips/byField?sort_order=asc&field=duration_minutes&date_lte=2025-12-31&size=1&date_gte=2025-01-01 HTTP/1.1" 200 OK
API Endpoints
- /searchTrips
- /topTrips/byField
- /locations/pickup/top
- /locations/dropoff/top
- /stats/frequentTimeIST
- /stats/fareStatsByTimeIST
- /topTrips/stats/totalFare
- /topTrips/stats/totalDuration
- /topTrips/stats/totalDistance
- Now, the
Fast APIis ready to serve.
AWS Setup
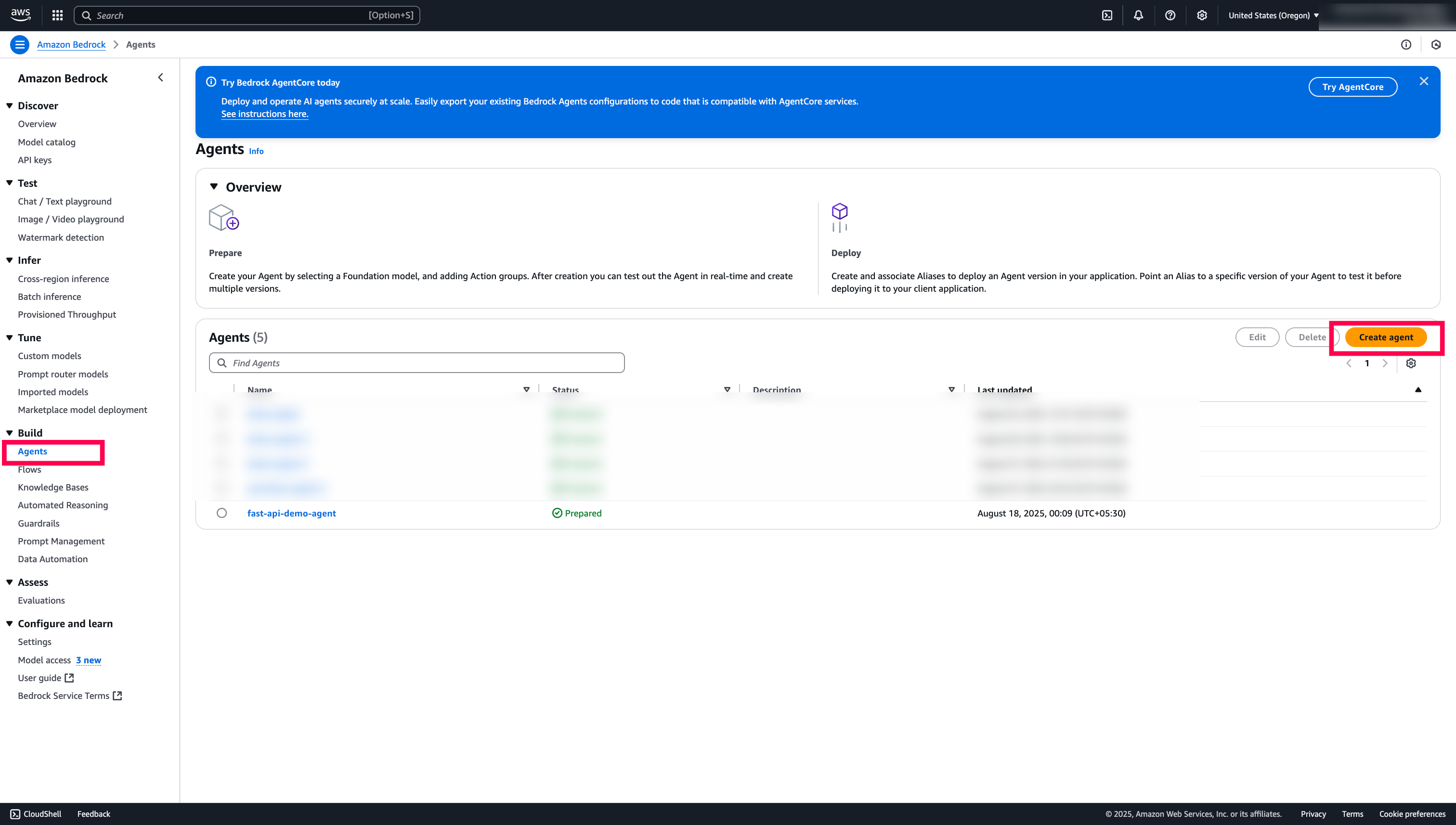
-
Login to your AWS Account and the specific region. Go to AWS Bedrock. Make sure, you have
IAM Permissionsset to use theBedrock Agents. -
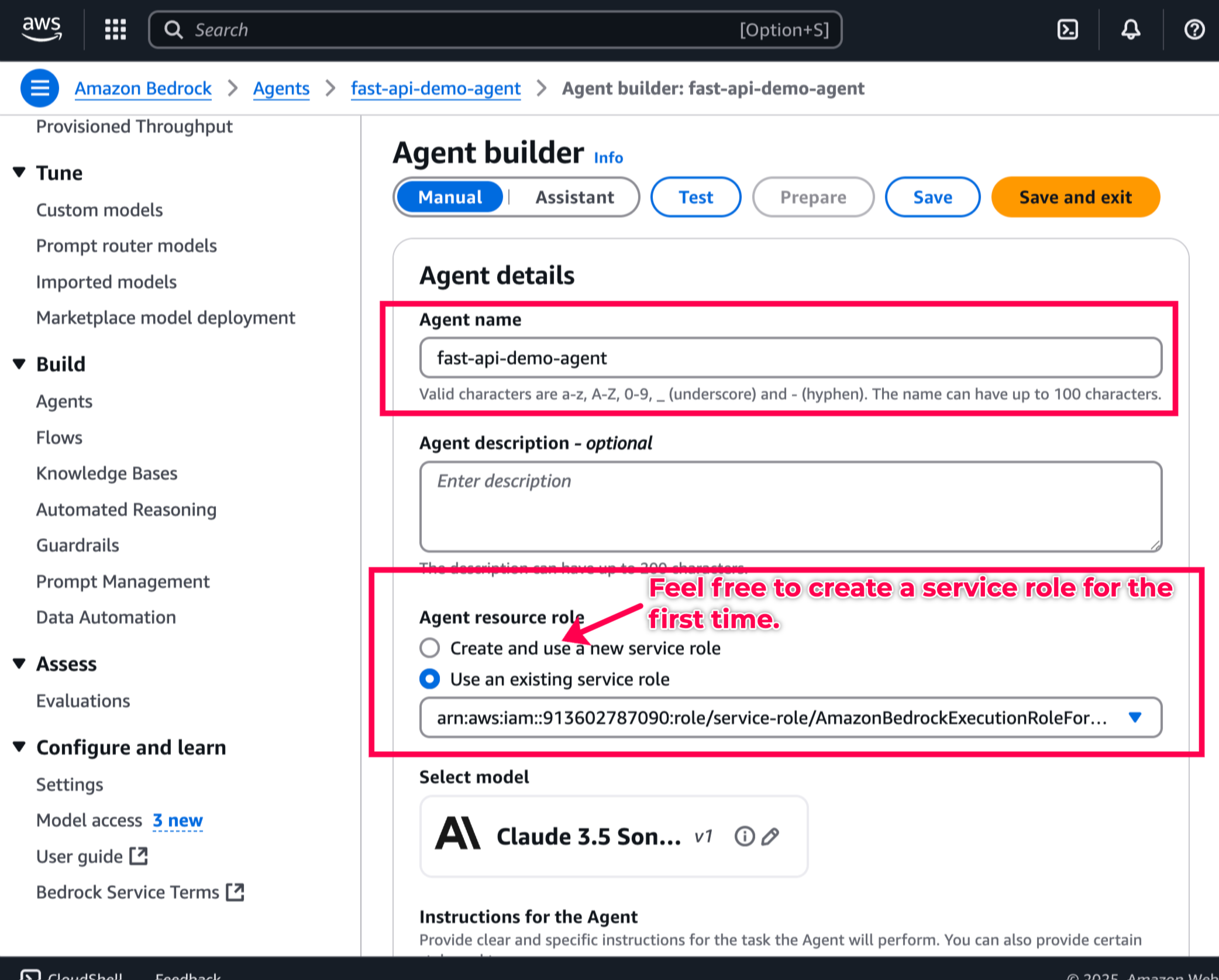
Create a
Bedrock Agent.
-
Under Instructions for the Agent, copy-paste this prompt.
-
Add a new
Action Groupswith theopenAPI schemaand theLambda function.
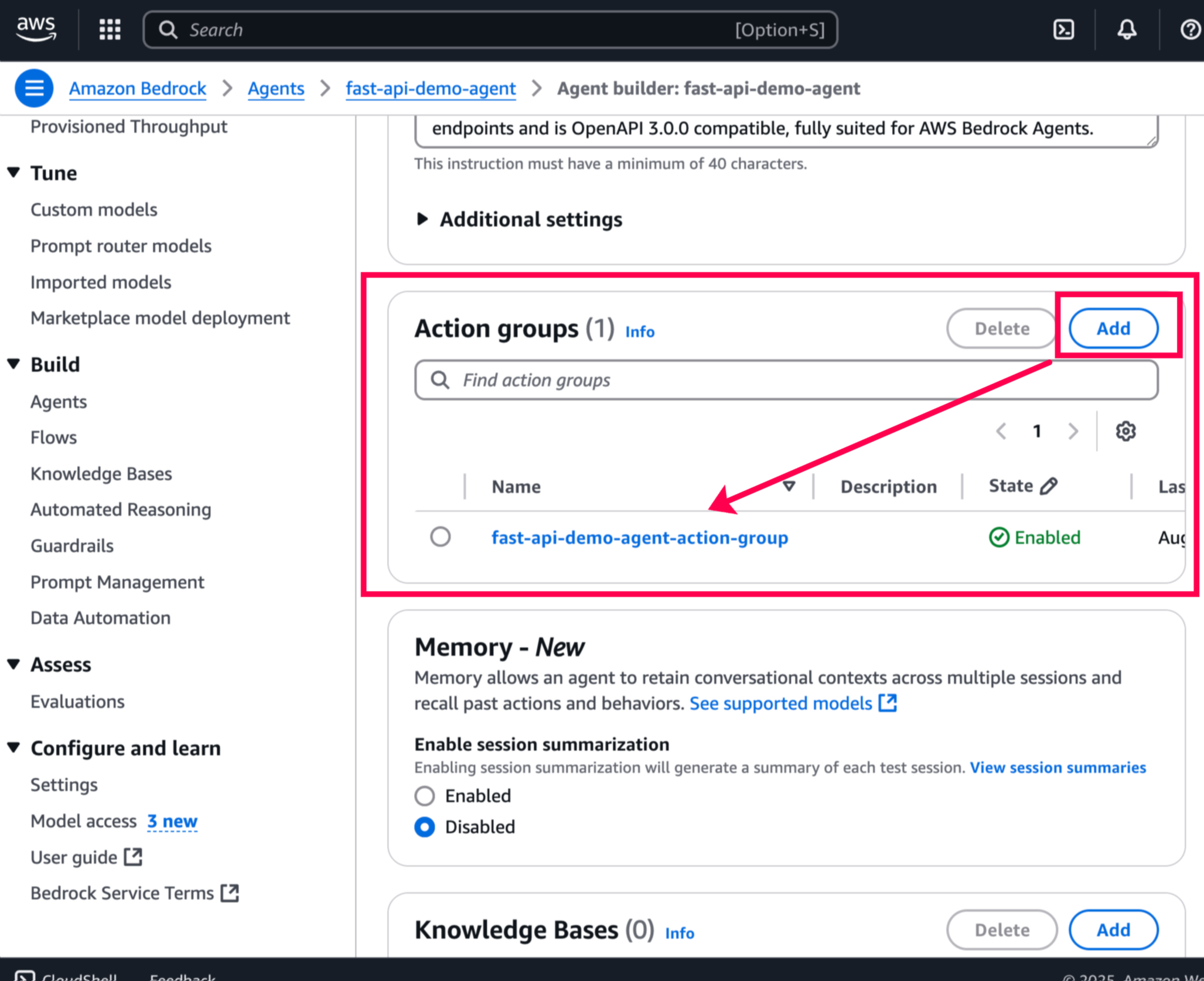
-
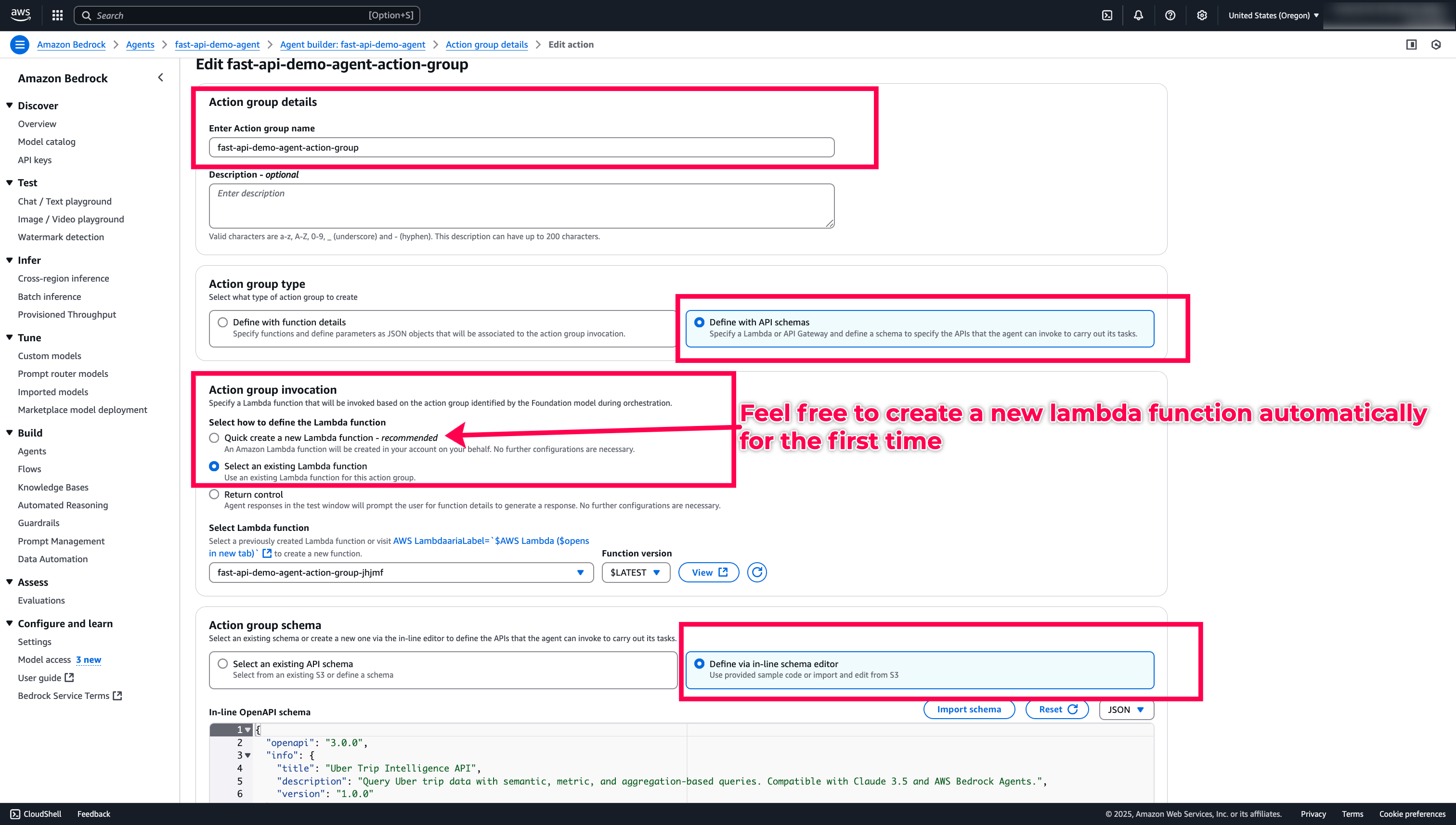
Copy-paste the
openAPI Schema 3.0.0from here. and save the Agent Buider. -
Now, the Agent Builder, create a new Lambda function for us. Let’s go to
AWS Lambdaandupdate the codeas here.. -
Also, as the
requestsdependencies are unvailable, I have bundled it so, we can directly import it from Lambda and finally, deploy the Lambda code. Make sure to update theNGROKPublic Url.
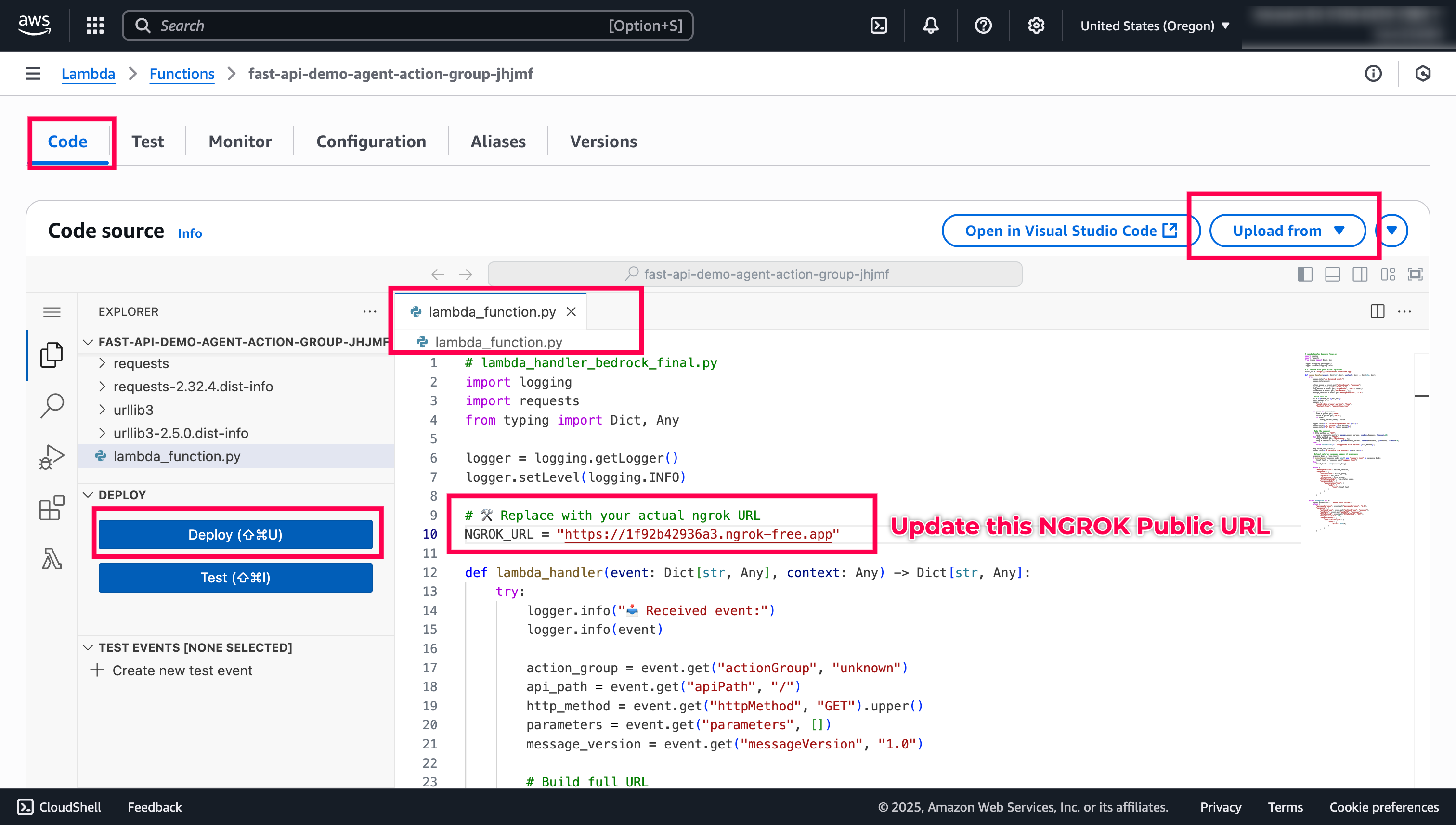
Quick Tip: Enable Cloudwatch logs to understand what’s happening in the Lambda side
- Once, Lambda is deployed successfully, you can go back to Agent Builder and please hit
save, let it load for a couple of seconds and hitPreparetoTestthe agent.

- Now, let’s ask the questions to test the agent.
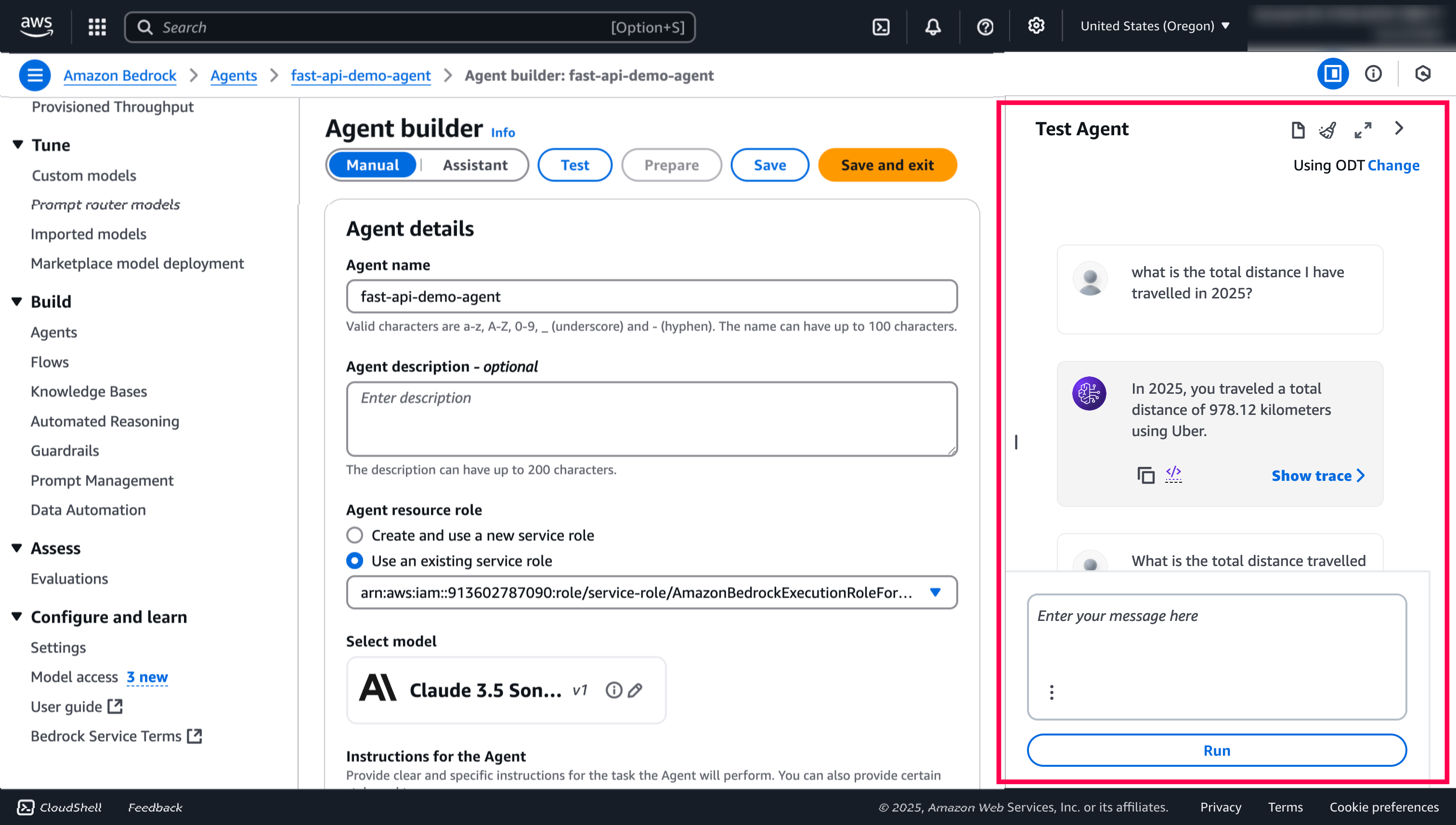
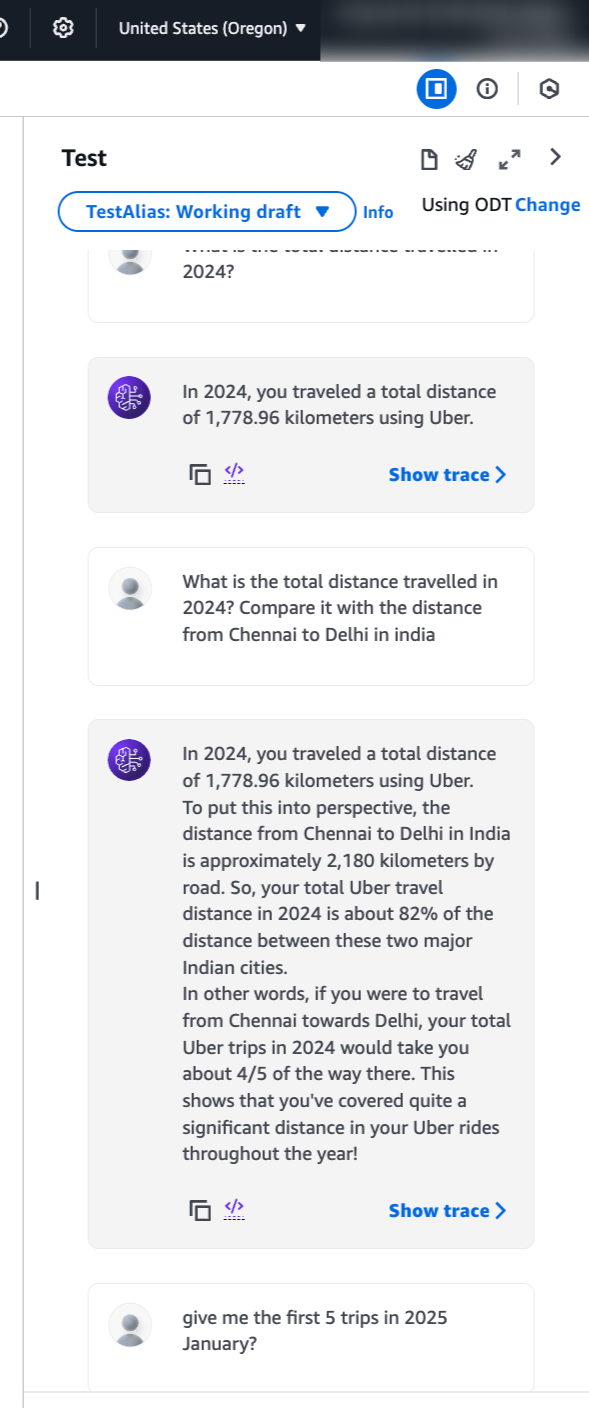
- That’s it. Start to play around with the questions on the Uber trips and try to modify the Fast APIs and queries. You can check the logs in the
Python Fast API applicationas well.
Additional References:
- Basic Queries to test in Kibana DevTools, refer queries.md.
- How start with Semantic Search in Elastic
- What are Search Approaches, why is it important?
- Let’s learn to build your Search Queries
- Usage of Built-in GMail Connectors
- Elastic Playground, a quick overview
Low-Level Analogies:
- How Elastic plays a bigger role in Vector Space
- Let’s dive deeper on Elasticsearch BBQ vs Opensearch FAISS
- Global Benchmark’s on Search Engine
- Gobal Benchmark’s on Vector DBMS